Azure Container Appsのワークロードプロファイルを試す②
前回の記事はこちら。コンテナアプリについての概要や試したいことは前回記事に書きました。今回はやり残したことをやってみます。
試してみる事
コンテナアプリは前回作成したものを引き続き使用します。
- サーバスペックをカスタマイズしたアプリ(前回の記事)
- 仮想ネットワークからの通信のみを許可したアプリ(前回の記事)
- 同じコンテナアプリ環境上にあるコンテナからの通信のみを許可したアプリ(前回の記事)
- Azure Filesをマウント
- スケーリング規則の作成
Azure Filesをマウント
コンテナアプリにAzure Fileをマウントさせます。ドキュメントを見るといくつかやり方があるようですが、今回は「コンテナアプリ環境にマウント設定」→「個別のコンテナアプリに適用」の手順で行きたいと思います。
まずはストレージアカウントを作成します。特筆することはないので説明は省略します。
後ほど使うのでストレージアカウントのアクセスキーは控えておきましょう。
では続いて今作成したAzure Filesを「コンテナアプリ環境」にボリュームとして設定します。おさらいですが、コンテナアプリ環境はコンテナアプリを作るための土台のようなリソースです。
「コンテナアプリ環境」→「Azure Files」→「追加」にて、追加するAzure Filesの名前やアクセスモードを設定します。

忘れずに保存ボタンを押しましょう。

コンテナアプリ環境に設定が出来たので、次は実際にコンテナアプリにマウントさせます。
ただ、どうもポータル画面からはうまく設定が出来なかったのでここからはAzure CLIを使っていきたいと思います。お手元のPCにAzure CLIがインストールされていればそちらから、そんなのめんどいよという方はazure portalのcloudshellを使ってやってみましょう。今回はcloud shellを使ってみます。
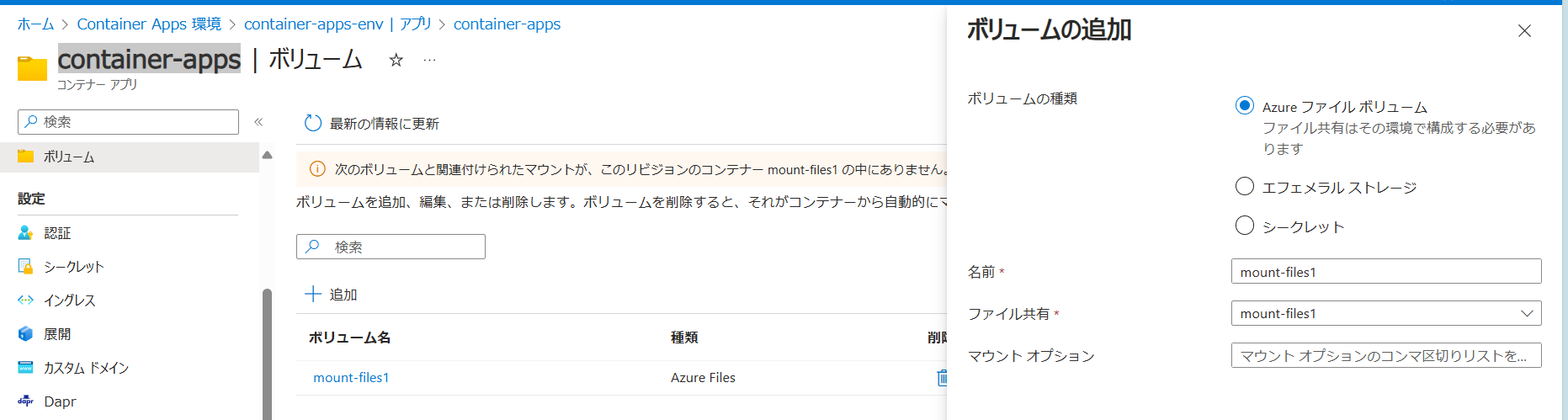
まず、マウントさせるAzure Filesをコンテナアプリに設定します(手順①)。これはポータル画面から出来てボリュームの追加から設定します。ちなみに、ここでの名前は「コンテナアプリ内」で使用する名前なのでコンテナアプリ環境で作成した名前とは異なっていても構いません。
次に現在のコンテナアプリの設定をYAMLファイルにエクスポートします。名前とリソースグループ名は適宜変えましょう。下記コマンドを打ったらapp.yamlというファイルを見てみましょう。
az containerapp show --name $CONTAINER_APP_NAME --resource-group $RESOURCE_GROUP --output yaml > app.yaml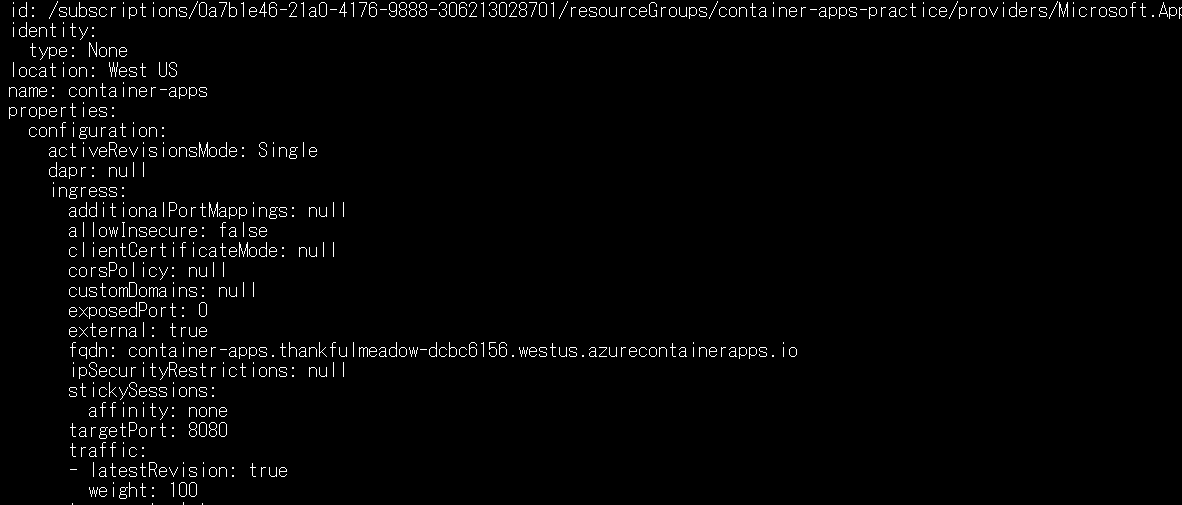
このファイルにマウント設定の項目を付け足してデプロイをします。公式曰く、template.volumesに手順①で設定したボリューム設定を、template.conatiners.volumeMountsにマウントさせるパスを書け、との事です。
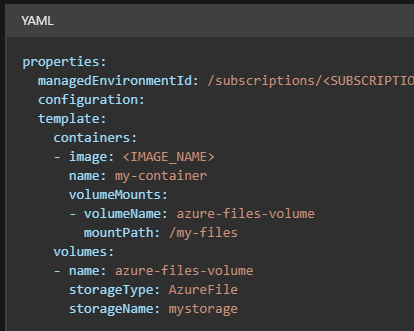
という事でこれを反映した私のymalはこちら。コンテナアプリ内の/mnt/testにマウントさせるようにします。volumeNmaeはvolumesで定義した名前を書きます。
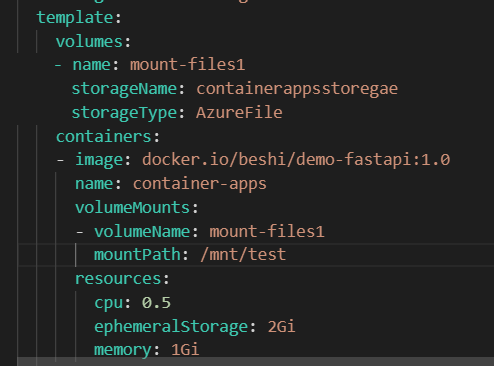
修正が出来たら下記コマンドでアップデートをします。
az containerapp update --name $CONTAINER_APP_NAME --resource-group $RESOURCE_GROUP --yaml app.yaml --output table
デプロイが完了していれば
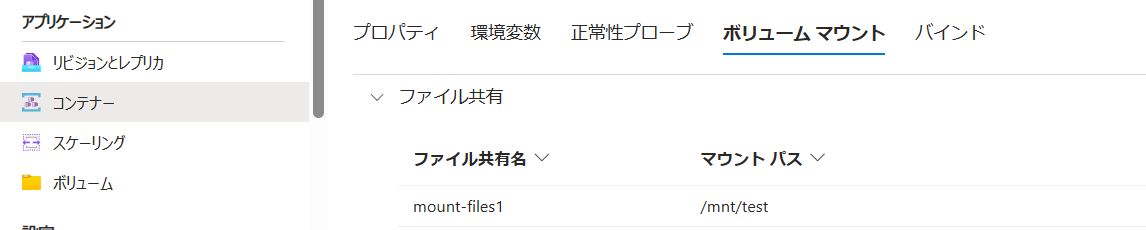
このように表示されます。せっかくなのでコンソールに入って新しいファイルを作成してみると・・・

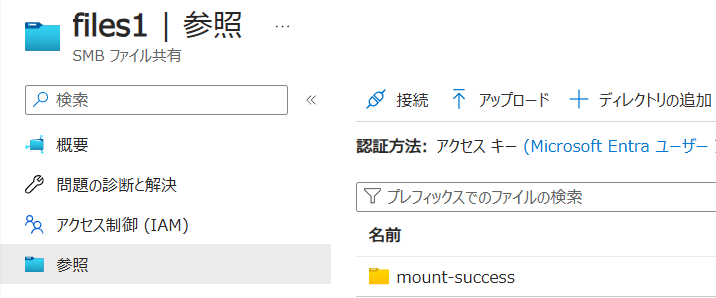
見事にマウントが出来ているようですね!アクセス権は読み取り専用にも出来るので要件に合わせて作成しましょう!
スケーリング規則の作成
最後に目玉と言っても過言ではないスケーリング規則の作成の作成をします。今回行うのは次の2つです。本当はイベント駆動もやろうかと思ったのですが、それは「コンテナアプリジョブ」という最近出来たサービスの方がよりらしい使い方が出来そうなのでそちらで試します。
- HTTP同時要求数
- CPU使用率
HTTP同時要求数
これはポータル画面で設定できる標準的な機能です。
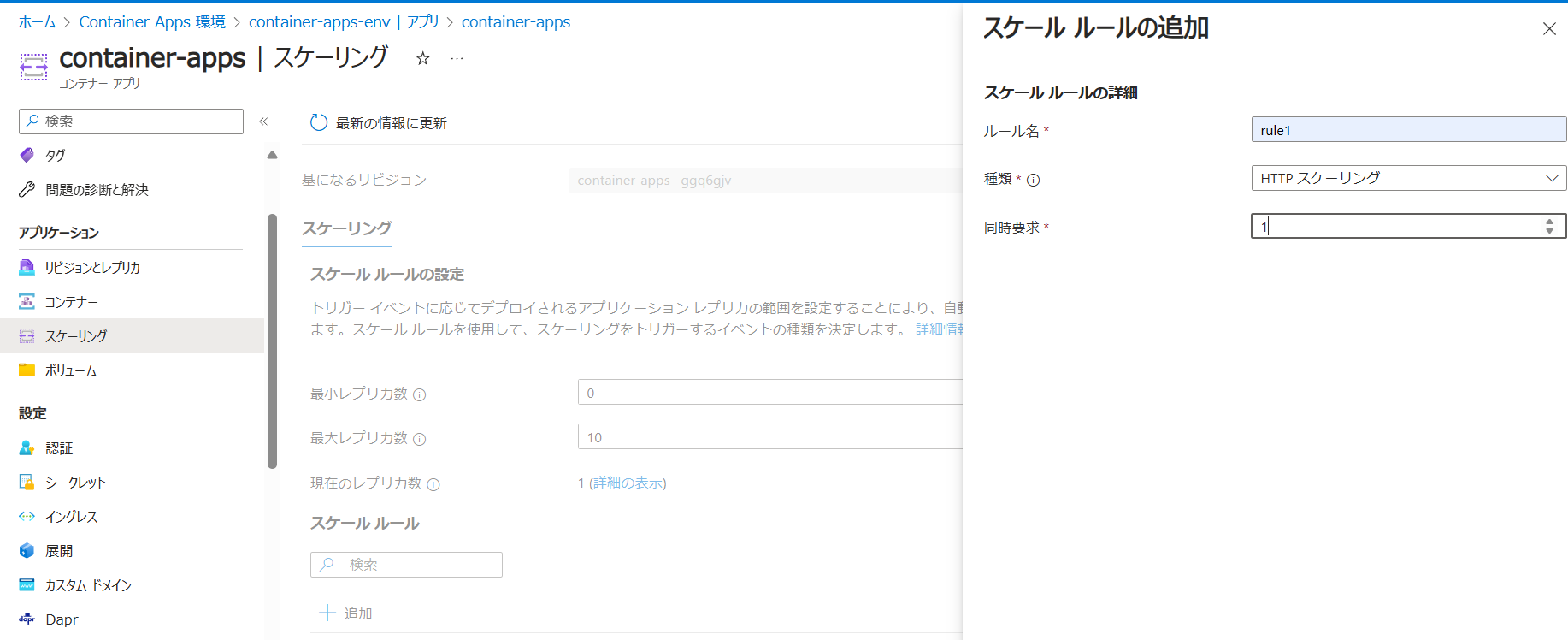
今回の設定では最小が0,最大10までスケーリングを行い、1秒あたり1回のリクエストでスケーリングをする設定にします。この1秒あたり、というのは15秒間の平均だそうです。
設定してしばらくすると、レプリカ数は0になっている事が確認出来ます。
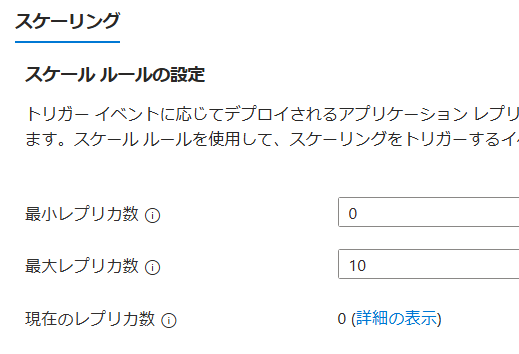
この状態からアプリへのGETメソッドを大量にしてみます。ただし、今現在0なので最初の1リクエストで多分1個スケーリングされると思います。その状態から30秒間で30回リクエストをすれば15秒の測定回×2で3レプリカになるはずです。では地道にやってみよう。
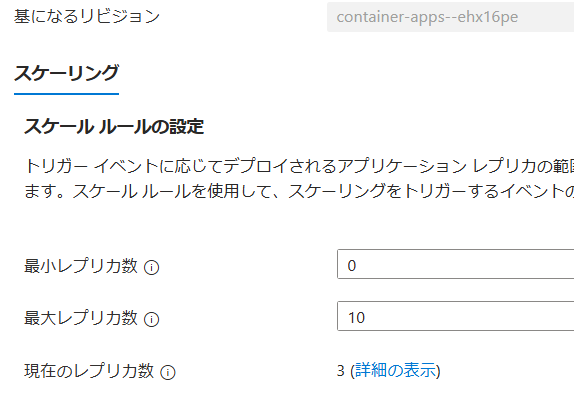
という事で手作業ではありますが(記事上では何やったかよく分かんないとは思いますが・・・)リクエストを送り続けてスケーリングを3にしました。実際のメトリックがどれだけ反映されているかはちょっと不透明ですが、とにかくスケーリングは成功です。
CPU使用率
続いてはCPUの使用率によるスケーリングを試してみます。こちらはKEDAのスケーリング機構を利用して行われるそうで、公式サイトに記載のあるメトリックであれば実装することが出来ます。
KEDAを用いた実装には次の手順でやると良さそうです。まずはKEDAサイトから使いたいメトリックのトリガーの項目を見ます。
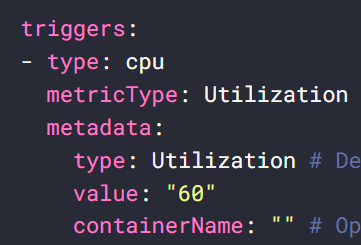
ちなみに意味は

だそうです。コンテナアプリのデプロイコマンドにスケーリング規則を追加する際に、ここでのtypeとmetadata項目を使用します。
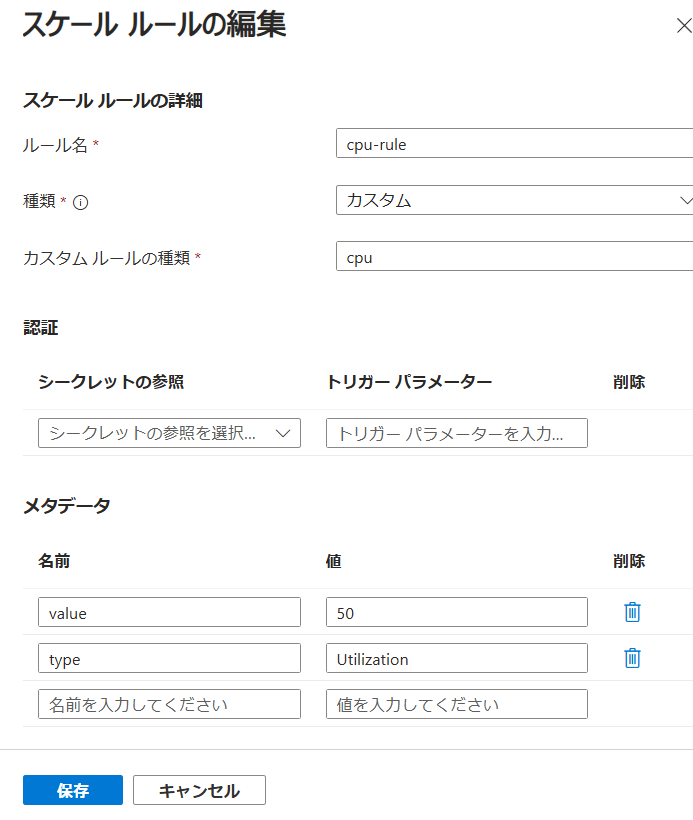
スケーリング規則の追加で上図のように設定をします。「カスタムルール」にはトリガーの「type」を、「メタデータ」にはmetadat欄に記載のある項目を転記します。今回は純粋なCPU率が50%でスケーリングするようにします。
では実際に実験します。コンソールからcpu使用率を確認すると・・・
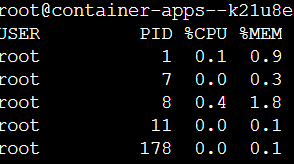

となっています。今回デプロイしたコンテナは到底、高負荷な状態にはなりえないので強制的に負荷をかけてみます。高負荷をかけるおなじみのコマンドyes >/dev/null &でcpu使用率は50%を超えました。
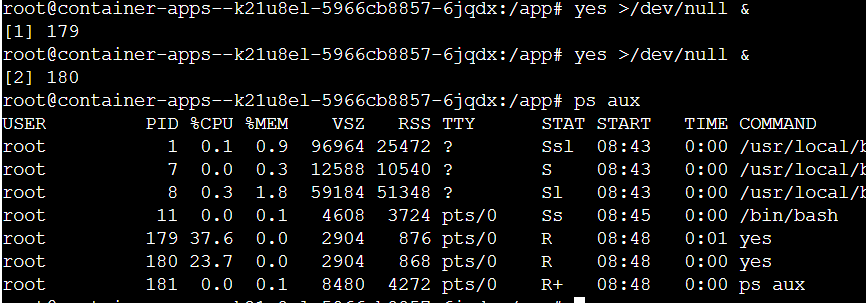
しばらく経つとこのようにスケーリングされました。
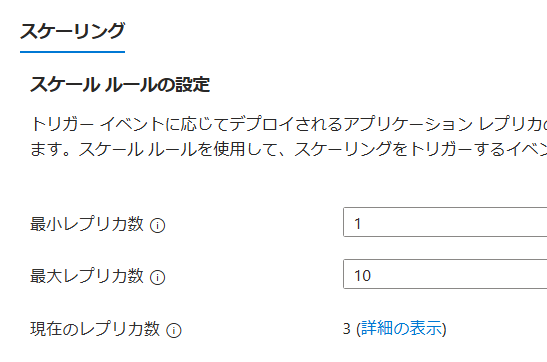
ちなみにこの計算方法ですが、KEDAのサイトにもあるようにコンテナを指定しない場合はすべてのコンテナに対しての割合を測るようです。つまり、最初のコンテは0.5cpuでデプロイしておりまして、まずその60%程度を使用したため1つスケーリングされます。この後がよく分からないのですが、スケーリングされた事で合計1cpuありますから、相対的に見て半分の30%を使用していることになるはずです。しかしながら実際はもう一つレプリカが作成されています。最初の一つはノーカンなのか、はたまた計算方法が違うのか・・・ここがちょっと疎いところです。詳しい人いたら教えてください。というかこの計算理解出来ていなかったらスケーリング規則作れないじゃん、とも思いますがまあね。
・・・と思ったんですがどうもいきなり3つレプリケートされているようです。
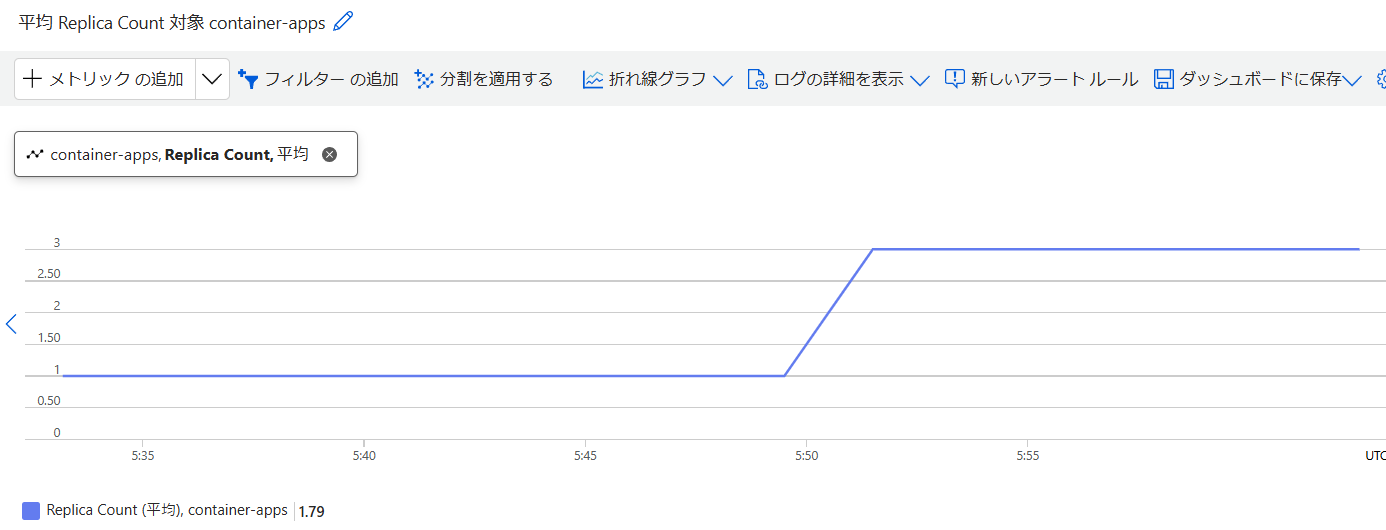
んーどうもよく分かりませんな。ちなみにクーリングタイムは5分必要らしいです。
でもまあ一応スケーリング規則を作成することが出来たのは間違いないので今回の記事はこの辺にしておきましょうか。
もし機会があれば今度はイベント駆動型のコンテナアプリを試してみたいと思います。これはこれでAzure Functionに近い使い方が出来る気がしているのでぜひやってみたいですね。
以上お付き合いいただきありがとうございました